Build mobile and desktop apps for
any OS using HTML, CSS, and JavaScript. Connect
users with modern P2P that can make the cloud
entirely optional.
Features
Lean & Fast
Starts with a ±20Mb memory footprint, and 1.5Mb binary distributable on desktop, ±13Mb on iOS and Android.
A Secure Runtime
Socket is not a framework, SDK or library. It's a runtime that can create a strong boundry between developer code and the user's operating system.
Use Any Frontend
All the standard browser APIs are supported, so you can use your favorite front-end libraries to create UIs! React, Svelte, or Vue for example.
Use Any Backend
The optional backend can be written in any language, Python, Rust, Node.js, etc.
Local First
A full-featured File System API & Bluetooth ensure it's possible to create excellent offline and local-first user experiences.
Native P2P
Built to support a new generation of apps that can connect directly to each other by providing a high-performance UDP API.
Quick Start
Install
The easiest and fastest way to install is with npm. Otherwise, Node is not required and you can install directly from source with curl
in Bash or iwr in PowerShell.
npmcurliwr
npm i @socketsupply/socket -g
Powershell Users must enable local script execution by issuing the following command... Start-Process powershell -verb runas -wait -ArgumentList "Set-ExecutionPolicy Bypass -Force".
By default, npm on macOS installs global packages to a system location. This may result in permissions errors for regular users, The solution is to change npm's global prefix by uninstalling the top level Socket package.
sudo npm uninstall @socketsupply/socket -g
Make the actual changes.
sudo npm config set -g prefix ~/.local
mkdir -p ~/.local
sudo chown -R $USER ~/.local# In case ~/.local contains folders owned by root
npm i @socketsupply/socket -g
To test, run the following command and it should output a path in ~/.local.
which ssc
. <(curl -s -o- https://socketsupply.co/sh)
This option will install by compiling from source (MacOS or Linux).
iwr -useb https://socketsupply.co/ps | iex
This option will install by compiling from source (Windows).
Powershell Users must enable local script execution by issuing the following command...
Start-Process powershell -verb runas -wait -ArgumentList "Set-ExecutionPolicy Bypass -Force".
Develop
The Basics
Open a terminal. Create a new project directory and change into it. Then, initialize a new project.
ssc init
This will produce a minimum set of project files that has the following file system layout...
You can open the index.html file to take a look at it. Modify it if you like. Then, build an app from the files.
ssc build -r
Congrats! 🎉 You just built a native application using nothing more than html and a single CLI command.
We provide a utility called Create Socket App,
which should be instantly familiar to anyone who knows Create React App.
npm create socket-app will create a new Socket project with all the basic files needed
to get a project started including a package.json, socket.ini, and src/*.
Content-Security-Policy
Socket apps are served from the file system. They are subject to the same security restrictions as a web page.
This means that you will need to add a Content-Security-Policy header to your index.html file.
The ssc init command will add a default policy for you, but you may need to modify it depending on your needs.
The socket: and ipc: schemes are used by the Socket runtime internally to resolve built-in modules and
communicate with the main process. The http://localhost:* and ws://localhost:* schemes are used to connect
to a local dev server when using the --port flag.
The only requirement from Socket is that you provide a socket.ini file at the root of the project.
So a typical Socket project can have any arbitrary file structure that works for you
and your team.
In fact, Socket runtime will behave just like your average web server when it comes to navigating
between pages. An example might look like this...
Some apps do computationally intensive work and may want to move that logic into a backend. That backend will be piped to the render process, so it can be any language.
This is what you see on your screen when you open an app either on your phone or your desktop.
The Socket CLI tool builds and packages and manages your application's assets. The runtime abstracts the details of the operating system so you can focus on building your app.
This is plain old JavaScript that is loaded by the HTML file. It may be bundled. It runs in a browser-like environment with all the standard browser APIs.
This is plain old CSS that is loaded by the HTML file.
This is plain old HTML that is loaded by the Socket Runtime.
HTMLJavaScriptCSSBackend
//// All JavaScript is optional, even bundling isn't necessary if you're using pure ESM.// An index.js file generally waits for the DOM to be ready before getting started.//import fs from'socket:fs/promisies'import process from'socket:process'asyncfunctionmain () {
console.log(process.platform)
console.log(await fs.readFile('index.html'))
}
window.addEventListener('DOMContentLoaded', main)
The backend is completely optional. We recommand building your app entirely
within the runtime. Unlike older runtimes, Socket is fully sandboxed.
// The backend can be any program that can reads stdin and writes to stdout.// Below is an example of using a javascript runtime as a backend process.import socket from'@socketsupply/socket-node'// send an event to the frontendawait socket.send({
window: 0, // send event to the main windowevent: 'ready',
value: { // the data to send (optional)message: 'Hello, World'
}
})
// backend gets a "calculate" event from the frontend// it gets the window id so it can send the result back to the right window// it gets the data so it can do some calculations
socket.on('calculate', async ({ data, window }) => {
// do some calculationsconst value = await doCalculations(data)
// send the result back to the frontend
socket.send({
event: 'calculated',
window,
value
})
})
User Experience
It may be tempting to add a script tag that links to some online resources, for example a CDN's copy of your
favorite library or some fonts. We DO NOT recommand this. We recommend adding these resources LOCALLY. This will
drastically improve user experience and privacy. This will mean your app can only be used while a user is online,
and it will be slow for anyone with limited bandwidth. Consider reading our section on local first development.
Logging
On all platforms, console.log will simply write to stdout (the terminal where you launched the app from).
When you open the console or write console output, memory usage
will increase, in some cases significantly. This is because the console will
retain objects and instrument the DOM. The memory may be released
when you close the inspector but the timeframe isn't guaranteed.
Live Reload
From The File System
ssc build command has a --watch flag that will watch your files and rebuild
when they change. You will also need to enable the webview to reload when a file
changes. You can do this by setting [webview] watch = true in your socket.ini.
Specify files and directories to watch with [build.watch] sources[].
# configure your project to watch for sources that could change when running `ssc`[build.watch]
sources[] = src/file/to/watch.js
sources[] = src/ # also works on directories# tell the webview to watch for changes in its resources[webview]watch = true# configure webview to reload when a file changes, this is `true` by default[webview.watch]reload = true
Run ssc build --run --watch to build your app. Now if you make changes to your files that
are specified in the [build.watch] section of your socket.ini file, the
app will automatically rebuild and, if the [webview.watch] reload is set to
true, the app will reload.
From A Web Server
The --port and --host flags that can load your app from a dev server.
This is the most flexible way to enable live reload with third-party dev server,
like the one that comes with Vite or Webpack.
The dev server will automatically reload your app when you make changes to your files.
Run the dev server, copy the port and run next command in the another tab of your terminal.
ssc build -r --port=<port-number>
If you run your web server on a different host, you can specify it with the --host flag.
Now the app will be loaded from the dev server. If you make changes to your
files, the app will automatically reload.
This can enable HMR (Hot Module Replacement) if your dev server supports it.
Build destination
You may need to tell your build script the output location. The ssc command
can tell you the platform-specific build destination. For example.
./myscript `ssc print-build-target`
Alternatively, you can use the config option [build.script] forward_arguments = true in your socket.ini file.
[build.script]forward_arguments = true
This will pass the build arguments to your build script as a command line argument.
For example, if your build script is ./build.js and you run ssc build -r, the
build script will be called as ./build.js <path-to-build-target>.
[build.script] forward_arguments may be deprecated in the future.
Debugging
In general, the Web Inspector should provide you with everything you need to
build and debug your program. You can right-click anywhere on the window of a
development build to open the Web Inspector.
On iOS, you can use Safari to attach the Web Inspector to the Simulator. In the
Safari menu, navigate to Develop -> Simulator -> index.html. This will be the
exact same inspector you get while developing desktop apps.
On Android, you can use Chrome to attach the Web Inspector. Open Chrome and
enter chrome://inspect into the URL bar.
In some advanced cases, for example, when you are developing native add-ons, you
may want to launch lldb and attach to a process, for example...
process attach --name TestExample-dev
Simulators And Emulators
If you're developing for a mobile device, you may want to try it on the
simulator before installing it onto the device. At this point, we can create a
build for the iOS simulator or Android emulator (add the -r flag to also run
it).
There may be platform exceptions that require a decision from the developer, for
example the bevel and notch/island on iPhone is different from Android.
In your index.js you can set a property on the body tag that represents the OS.
import process from'socket:process'document.body.setAttribute('platform', process.platform)
if (process.platform === 'mac') {
// run some very specific code for mac
}
Then from your CSS you can add respective styles...
This guide will help set up your development environment for building Socket
apps, and step-by-step on how you can deploy to Android and iOS devices.
Depending on how you obtain Socket, you may be prompted to install some build
dependencies, but you can also skip this step to save some time.
If you're installing from a package manager...
NO_ANDROID=1 NO_IOS=1 npm i @socketsupply/socket -g
If you're installing from source...
NO_ANDROID=1 NO_IOS=1 ./bin/install.sh
You can always go back to install platform-specific build dependencies. The
setup utility will prompt you to install the necessary tools, for Android,
this will include Android Platform Tools & Command Line Tools, and OpenJDK.
ssc setup --platform=android
Android
First Time Setup
If you have never developed for Android before, you'll need to download and install some software.
Download time is greatly determined by the underlying platform's requirements. In this case, the full set of tools and assets required for building Android apps entails about 5.5GB of downloads from Google's servers.
The total extracted size of the Android build tools is 12.0GB.
Connection Speed*
Estimated Time
1Mbps
~13 hours
25Mbps
~32 minutes
100Mbps
~8 minutes
These estimates don't include your development environment hardware,
times will vary. The connection speed refers to your actual data throughput
to the relevant servers, which could be slower than your advertised
connection speed.
Existing Setup
Setting
Expectation
ANDROID_HOME
The sdkmanager that ships with Android Studio doesn't currently work (Users are expected to use the GUI), so, for now, we aren't able to use it. If you already have ANDROID_HOME set, ssc setup --platform=android will simply ignore that installation and ask you to set up the Android SDK in a new location. Once ssc is up and running, it will read ANDROID_HOME from .ssc.env, so you can have both Android Studio and ssc running concurrently for Android development.
JAVA_HOME
Our runtime libraries currently require OpenJDK 19 to build. If you already have this version or later installed, great. ssc setup will find it, otherwise, you will be prompted to install OpenJDK in a new location.
Development
Before you can deploy to a physical Android device, you will need to enable USB Debugging on the device.
USB Debugging
Disconnect any USB cables from your Android device
Go to Settings (Usually swipe down from the top of the screen, tap the gear :gear: icon)
Tap About phone
tap Software information
Tap Build number seven times - The time between taps should be about 1 second
Your phone should say "Developer Mode enabled"
Go back to Settings
Tap System
Tap Developer options
Tap to enable USB debugging
Connect our Android device to your workstation using a known working USB cable
Look for a prompt to "Allow USB debugging?" on your Android device
You will be prompted to install Android developer dependencies if you haven't done so already.
Run It On Your Device
First build, codesign and package the app.
ssc build --platform=android -c -p
Ensure the device is plugged into your computer and then issue the install command.
ssc install-app --platform=android
🎉 You're ready.
iOS
This section covers how to run and debug Socket apps on iOS.
iOS apps can only be developed on macOS with Xcode installed.
You will be prompted to install Android developer dependencies if you haven't done so already.
Requirements
You will need Xcode to build for iOS and test on an iOS Simulator.
You don't need to open Xcode when you develop with Socket, but you will need it to install the Command Line Tools.
If you don't have them already, you can run the command xcode-select --install.
Register your devices for testing. You can use ssc list-devices
command to get your Device ID (UDID). The device should be connected to your mac by wire.
Create a wildcard App ID for the application you are developing.
Write down your Team ID. It's in the top right corner of the website. You'll need this later.
Code Signing
Before we can actually run any software on iOS, it must be signed by Xcode using the certificate data
contained in a "Provisioning Profile". This is a file generated by Apple and it links app identity, certificates
(used for code signing), app permissions, and physical devices.
Open the Keychain Access application on your mac (it's in Applications/Utilities).
In the Keychain Access application choose Keychain Access -> Certificate Assistant -> Request a Certificate From a Certificate Authority...
Type your email in the User Email Address field. Other form elements are optional.
Choose Request is Saved to Disk and save your certificate request.
Create a new Apple Development or iOS App Development certificate on the Apple Developers website.
Choose a certificate request you created 2 steps earlier.
Download your certificate and double-click to add it to your Keychain.
You may need to set the certificate to "Always Trust" in the Keychain Access application.
Create a new iOS App Development profile. Use the App ID you created with the wildcard.
Pick the certificate that you added to your Keychain two steps earlier.
Add the devices that the profile will use.
Add a name for your new developer profile.
Download the profile and double-click it. This action will open Xcode. You can close it after it's completely loaded.
Place your profile in your project directory (same directory as socket.ini). The profiles are secret, add your profile to .gitignore.
Configure your socket.ini file with the following values:
Set the distribution_method value in the [ios] section of socket.ini to development
Set the codesign_identity value in the [ios] section of socket.ini to the certificate name as it's displayed in the Keychain or copy it from the output of security find-identity -v -p codesigning
Set the provisioning_profile value in the [ios] section of socket.ini to the filename of your certificate (i.e., "distribution.mobileprovision").
We recommend to have these values in .sscrc file if you are working with a team. See Configuration basics for more details.
Development
Before we deploy to a device, we usually want to preview our work. Although we can run and preview the code as a desktop app pretty easily, we can also use the iOS simulator to see what it looks like.
ssc build -r --platform=ios-simulator
Run It On Your Device
First build, codesign and package the app.
ssc build --platform=ios -c -p
Ensure the device is plugged into your computer and then issue the install command.
ssc install-app --platform=ios
🎉 You're ready.
Next Steps
The JavaScript APIs are the same on iOS and Android, check out the API docs.
Distribution Guide
Status: DRAFT
This guide covers distributing your apps into and outside of various ecosystems.
Apple
This is a guide to distributing apps on the Apple platform.
Register your devices for testing. You can use ssc list-devices
command to get your Device ID (UDID). The device should be connected to your mac by wire.
Create a wildcard App ID for the application you are developing.
Write down your Team ID. It's in the top right corner of the website. You'll need this later.
MacOS
Xcode Command Line Tools. If you don't have them already, and you don't have Xcode,
you can run the command xcode-select --install.
Open the Keychain Access application on your mac (it's in Applications/Utilities).
In the Keychain Access application choose Keychain Access -> Certificate Assistant -> Request a Certificate From a Certificate Authority...
Type your email in the User Email Address field. Other form elements are optional.
Choose Request is Saved to Disk and save your certificate request.
MacOS
Signing software on MacOS is optional but it's the best practice. Not signing
software is like using http instead of https.
Create a new Developer ID Application certificate
on the Apple Developers website.
Choose a certificate request you created 2 steps earlier.
Download your certificate and double-click to add it to your Keychain.
iOS
To run software on iOS, it must be signed by Xcode using the certificate data
contained in a "Provisioning Profile". This is a file generated by Apple and it
links app identity, certificates (used for code signing), app permissions,
and physical devices.
Create a new iOS Distribution (App Store and Ad Hoc) certificate on the Apple Developers website.
Choose a certificate request you created 2 steps earlier.
Download your certificate and double-click to add it to your Keychain.
When you run ssc build --platform=ios on your project for the first time, you may see the
following because you don't have a provisioning profile:
ssc build --platform=ios
• provisioning profile not found: /Users/chicoxyzzy/dev/socketsupply/birp/./distribution.mobileprovision. Please specify a valid provisioning_profile field in the [ios] section of your socket.ini
Create a new Ad Hoc profile. Use the App ID you created with the wildcard.
Pick the certificate that you added to your Keychain two steps earlier.
Add the devices that the profile will use.
Add a name for your new distribution profile (we recommend naming it "distribution").
Download the profile and double-click it. This action will open Xcode. You can close it after it's completely loaded.
Place your profile in your project directory (same directory as socket.ini). The profiles are secret, add your profile to .gitignore.
Configuration
MacOS
Set the [mac] codesign_identity value in socket.ini to the certificate name as it's displayed in the Keychain or copy it from the output of security find-identity -v -p codesigning
Set the [apple] team_identifier value in socket.ini to your Team ID.
iOS
Set the [ios] distribution_method value in socket.ini to the ad-hoc
Set the [ios] codesign_identity value in socket.ini to the certificate name as it's displayed in the Keychain or copy it from the output of security find-identity -v -p codesigning
Set the [ios] provisioning_profile value in socket.ini to the filename of your certificate (i.e., "distribution.mobileprovision").
Distribution And Deployment
ssc build --platform=ios -c -p -xd
To your device
Install Apple Configurator, open it, and install Automation Tools from the menu.
Connect your device and run ssc install-app <path> where the path is the root directory of your application (the one where socket.ini is located).
An alternative way to install your app is to open the Apple Configurator app and drag
the inner /dist/build/[your app name].ipa/[your app name].ipa file onto your phone.
The more a protocol relies on server infrastructure for communication
between users the more vulnerable it becomes, both technically and economically.
Centralized Client-Server
On one side of the spectrum, you have a client-server, where the network relies
entirely on server infrastructure. If the server is disrupted, the entire
application will not work. Mitigation in this case means adding load-balancers,
WAP, API Gateways, replication ingress and egress fees, and other expensive services.
Decentralized Client-Server
In response to over-centralization, and the consolidation of authority,
federated systems like Nostr, and Mastodon have emerged. A majority
of these networks still rely on a small amount of highly centralized server
infrastructure with the same costs. However, the costs are distributed to the
hobbyists, volunteers, and companies who have various incentives to participate
in the network. However, once the cost outweighs the incentives, many of these
nodes are forced to shut down, scale back, or find ways to subsidize which
aren't always aligned with the users of the service.
Solution
Decentralized P2P
On the other side of the spectrum, you have P2P which in theory can use the least
amount of server infrastructure (in some cases, none at all). Most importantly, a
network is considered P2P when peers in the network connect directly.
A node in the network can only be considered a peer when all other peers that it
connects to are of the same importance and have all the same responsibilities. A
P2P network is considered symmetrical when no peers have unique roles or
responsibilities. This is the most robust kind of network.
Network Type
Partition Tolerance
Fault Tolerance
Symmetrical
High
Low-Cost
Asymmetrical
Low
High-Cost
Local-First
Problem
Hosted software, like Web apps, which only run in the Cloud, has objective disadvantages.
The UI usually doesn't work when there is no connectivity.
The UI is frustratingly slow when there is low connectivity.
The data is only available when you are connected.
The operator may delete or sell your data on a whim.
The operator may observe or sell observations about your behavior.
The operator may go out of business and abandon your data at any time.
The operator may undergo ownership changes that don't align with your best interests.
Solution
Local-first is a software design pattern that fixes the problems described
above. The following solution is broken into four discrete goals.
Minimize Wait Times
Maximize Data Lifespan
Secure & Preserve Privacy
Progressively Connect
Minimize Wait Times
This means essential screens in the UI should never leave the user waiting for
something to happen.
Let's consider a chat app. The messages I've sent, the messages I've seen, and
any message I want to interact with, require a negligible amount of storage at
most. These can all be stored on my devices at a negligible cost.
A social media app is similar, a timeline with 1K recent items a very little
data. That data becomes less relevant as time goes on and so older posts can be
removed and newer posts can be added to the application storage or cache as
they are discovered.
In short, the data I've created or already seen is data that should be
negligible to store and trivial to make available. Loading, rendering,
searching, and sorting, all of that data should be instant.
Maximize Data Lifespan
Everything popular in Tech is eventually replaced. The frustrating thing is
when our data becomes trapped on a device because, imagine the data is in a
storage-optimized binary format that no one other than the software maker can
understand, the data would be considered dead once the vendor stops
maintaining that software.
As storage continues to become cheaper and devices become more powerful, it
becomes easier to use the same storage primitives on mobile as we do on desktop.
Sticking to well-known solutions like SQL-Lite or LevelDB to store JSON objects
makes it easy to reason about an export feature. This makes the data highly
portable and easier for the user to maintain ownership over it.
Secure & Preserve Privacy
With hosted software, all data is handled by a 3rd party and what they do with
that data is uncertain. But what is certain, is that a single, central repository
of all user data is appealing and vulnerable to a disgruntled or compromised
employee, and nation-state or independent hackers.
Socket encrypts all data at the network packet layer, this makes eavesdropping
hard. When packets are relayed by other peers because the intended recipient is
not directly available, packet routes are highly randomized and don't disclose
enough information about the sender or receiver to conclude about who is communicating
with whom. And since the majority of peers can also be
introducers, there is not enough static infrastructure for traffic-analysis attacks.
You should assume that all other peers in the network are potentially adversaries.
Do not elevate the responsibilities or test of any single peer in the network.
Rate limits are an essential tool that should only be relaxed when a peer is
verified with MLS.
Progressively Connect
The default state of the application should be to work without the Internet.
When network connectivity does become available, it should be assumed to be
unreliable. There may be a small window of opportunity to exchange data with
any other peers who are online. That opportunity is used by Socket's P2P
protocol to exchange unsent network packets with other peers, attempting to
become eventually consistent with other peers in your cluster and subclusters.
You can emit any arbitrary data Socket's P2P protocol, it will be queued up
and ready to exchange with other peers when you connect with them. Remember
that rate limiting is the golden rule of the protocol, and if you queue up too
much data, people may start rejecting it. So be considerate for your own sake.
P2P Guide
Status: DRAFT
Overview
P2P is an approach to building software that allows its users to communicate
directly. It offers increased privacy, security, and performance, as well as
reduced cost and complexity when compared to more traditional and less transparent
Cloud infrastructure. It's relevant to anyone building multi-user software on
a scale of small to large (millions of users).
P2P is also a broad term that can mean a lot of things to a lot of different
people. To clarify the conversation, we separate P2P info from 4 domains. Network,
Storage, Consensus, and Compute.
Our solution focuses exclusively on the Network. Our goal is to make sure you
can discover other computers and exchange packets with them in the most
reliable way while having the least impact on your application or its logic.
Criteria
Do not use more battery or storage than any other app.
Ensure continuity of the overall network regardless of the condition of any
other individual network resource.
Ensure communication regardless of the state of any well-known peers.
Goals
A front-end developer familiar with HTML, CSS, and JavaScript should be able
to create a fully functional chat app like Telegram, a social media app like
Twitter, a coordination app like Uber, or a collaborative content creation app
like Figma or Notion without needing any servers or Cloud services. Here's
the way we see these goals.
Complexity
Servers are natural bottlenecks (One server to many users), and scaling them up
quickly becomes a complex distributed system of shared state. A P2P network is
many users to many users, and although it is also an eventually consistent,
distributed system of shared state, the total complexity of all components
needed to create a robust P2P network is finite, and transparent. And unlike Cloud
services, since it's entirely transparent, it can be verified with formal
methods by anyone.
Security & Sovereignty
P2P is simply a networking technique, it's not more or less dangerous than any
other approach to computer networking. A P2P app is not more likely to contain
malicious code or perform unwanted behavior than any web page or client-server
application. P2P is entirely transparent which makes it easier to audit.
Conversely, Cloud services are a closed system — owned and operated by a
private third party. Most people can't audit them. With
Gov. Cloud, auditing is intermittent. There is always a non-zero chance for a
greater number of incidents than if every single bit was self-contained. Fewer
moving parts means less risk.
Cost
As your application grows, so do the costs of the services you use. Growth
usually means combining services from different providers and staffing the
experts to glue it all together.
How P2P Works
Many users communicate by sending all their data to one end-point; typically rented by a company from a Cloud hosting provider.
Many users communicate in coordination with each other, sharing only with each other, or in concert with existing services.
import { network, Encryption } from'socket:network'//// Create (or read from storage) a peer ID and a key-pair for signing.//const peerId = await Encryption.createId()
const signingKeys = await Encryption.createKeyPair()
//// Create (or read from storage) a clusterID and a symmetrical/shared key.//const clusterId = await Encryption.createClusterId('TEST')
const sharedKey = await Encryption.createSharedKey('TEST')
//// Create a socket that can send a receive network events. The clusterId// helps to find other peers and be found by other peers.//const socket = await network({ peerId, clusterId, signingKeys })
//// Create a subcluster (a partition within your cluster)//const cats = await socket.subcluster({ sharedKey })
//// A published message on this subcluster has arrived!//
cats.on('mew', value =>console.log(value))
//// A message will be published into this subcluster//
cats.emit('mew', { food: true })
//// Another peer from this subcluster has directly connected to you.//
cats.on('#join', peer => {
peer.on('mew', value => {
console.log(value)
})
})
IP Addresses & Ports
To get connected to the Internet, you get an account from an Internet Service
Provider (an ISP). For home or office Internet, your ISP gives you a router that
you plug into the wall. Once you have that, you connect your various devices to
it. On mobile, you also connect to a router, but you never see it. Every device
connects to the Internet through a router.
Everything that connects to the Internet needs an address. The purpose of the
address is to help other computers know where to deliver messages (packets).
Your router is assigned an IP address by your ISP. Your computer is assigned
a local IP address by your router. In fact, any computer you connect to your
router will get a unique local IP address. All of these addresses can change
at any time.
But IP addresses are not enough information to start communicating. Imagine your
computer is like an office building, its IP address is like the street address,
and every program that runs is like a different office in that building. Each
office gets assigned a unique number which we call the "internal port".
Routers & NATs
Now imagine lots of programs running on lots of computers all want to send
packets. To manage this, the router maintains a database that maps a program's
internal port and the IP address of the computer that it's running on to a unique
external port number. This is done so the router can ensure that inbound packets
always reach the program running on the computer that is expecting them. This is
called Network Address Translation, or NAT for short. And different routers
made by different manufacturers for different purposes can have different
behaviors!
Your computer’s local IP address isn't visible to the outside world, and the
router’s IP address isn’t visible to your computer, and neither are the port
numbers in the router's database. To make things even more difficult, if the
router sees inbound packets that don't match an outbound request, it will
usually discard them. Different routers may even assign port numbers
differently! All this makes it hard to get server-like behavior from your mobile
device or laptop. But with P2P, we want to listen for new packets from people we
don't know, kind of like a server. This is where it starts to get complicated.
Reflection
Before other programs on the Internet can send packets directly to a program on
your computer or device, they need to know your router's public IP address, and
the external port number that your router assigned to your program. They
also need to know what kind of NAT behavior to expect from your router.
This is determined by asking for our address and port info. It's important to
ask two other peers (and they must be outside of our NAT). If both peers respond
with the same port, we are behind an Easy NAT. If both respond with different
ports we are behind a Hard NAT. If we respond to an unsolicited query on a well-
known port, we are behind a Static NAT. We call this process of asking another
peer for address information "Reflection".
Reflection is where Alice asks two other peers for her external
IP address and port. Those two other peers, X and
Y, can be any arbitrary Static or Easy peers, but they must be
outside of Alice's NAT.
If Alice wants to talk to Bob, they both tell Cat their information. Cat
will send Alice Bob's address, port, and NAT type. Cat will also send Bob
Alice's address and port and NAT type. Now they have been introduced.
A peer that can introduce us to other peers is called an "introducer". An
introducer can be an iPhone, a laptop, or an EC2 instance, it could be anything as
long as it has an Easy or Static NAT type.
NAT Traversal
Now that Alice and Bob know each other's information, are ready to start the
process of initiating a "connection". We use UDP which is message based, so this
is only a connection in the sense that each peer knows about the other's address
information are they are expecting messages from each other. This process is
called NAT traversal (aka "Hole Punching"). Alice and Bob's NAT types will
determine how well this initiation will go.
If you've ever set up a Cloud VPS (like Amazon EC2), you've indirectly
configured its router to allow direct traffic on a particular port. This is an
example of a Static NAT. A peer with this kind of NAT will accept packets
without any extra work.
If Alice and Bob are both on Easy NATs, that means they are probably on phones
or home networks. The procedure is pretty simple. Alice must first send a
packet to Bob. This packet will fail to be delivered but will open a port on her
router. Bob does the same thing.
At this stage, the packets being sent are never received, they are only meant to open the port on the router that is sending them.
The router will maintain a port mapping in its database for ±30 seconds. Now is the time to start sending heartbeat packets so the port mappings don't expire.
Now that a port is open and the router is expecting to see responses addressed
to it, Alice and Bob can send messages and their routers will not consider the
messages unsolicited. But if either Alice OR Bob are on a Hard NAT, the process
is similar but using more ports and sending more control messages.
If Alice is on the Hard NAT, she opens 256 ports, and Bob immediately sends
packets until he receives a packet from Alice confirming that at least one of
his packets was received.
This generally works better than it sounds due to probability. For example, if
you survey a random group of just 23 people there is actually about a 50–50
chance that two of them will have the same birthday. This is known as the
birthday paradox, and it speeds up this guessing progress so that connection
times in this scenario are under a second, once the port is open it can be kept
open. And only about a 1/3rd of all NATs are Hard, so connection times are about
the same as they are in client-server architectures. Also, this whole process
doesn't work if both NATs are Hard.
Note: There is an optimization where you can check if the router supports port
mapping protocols such as PmP or PnP, but in our research, very few routers
respond to queries for these protocols.
Now you have a direct connection and you can try to keep it alive if you want.
But it will likely go offline soon, most modern networks are extremely dynamic.
Imagine taking your phone out to check Twitter for a few seconds, then putting
it back in your pocket. So the next part of our protocol is equally as important
as the NAT traversal part.
Disruption & Delay Tolerance
In modern P2P networks, all peers should be considered equally unreliable.
They may be online in short bursts. They may be online but unreachable. They may
be offline for a few seconds, or offline for a month. This protocol anticipates
these conditions in its design — any node, or any number of nodes are
able to fail and this will not affect the integrity of the overall network.
Let's say that Alice and Bob get connected and want to have a video chat. They
can send packets of data directly to each other. They may have minor network
interruptions that cause inconsequential packet loss. But what if Alice and Bob
are text messaging? A lot of the time this kind of communication is indirect
(or asynchronous). If Bob goes offline, how can he receive the subsequent
messages that Alice sends? This is where we need to dig into the protocol design.
Protocol Design
Stream Relay is a replicating, message-based gossip protocol, that follows the
criteria for Disruption Tolerant Networks.
In the simplest case, Epidemic routing in gossip protocols deliberately makes no
attempt to eliminate flooding. However, protocols such as MaxProp (John Burgess
Brian Gallagher David Jensen Brian Neil Levine Dept. of Computer Science, Univ.
of Massachusetts, Amherst), demonstrate optimizations that can outperform
protocols with access to oracles (An oracle being something like a Distributed
Hash Table, a Minimum Spanning Tree, or a Broadcast Tree).
A replicating protocol casts a wide net and yields faster response times and
higher hit rates, but in some cases there are arguments it will waste more
bandwidth.
In the paper "Epidemic Broadcast Trees" (Plumtree, Joao Leitao, et. al 2007),
the authors define a metric (Relative Message Redundancy), to measure the
message overhead in gossip/replicating protocols. However the paper was published
before the dominance of mobile devices and their usage patterns. It advocated
for the conservation of bandwidth using a "lazy push approach", which as a
trade-off, made it slower. It also introduced central services for calculating
trees to optimize routing. With mobile usage patterns, there is a smaller
window of time to satisfy a user request. So this optimization is no longer
relevant, especially if we factor the declining cost of bandwidth and the
increasing expectations for responses.
Stream Relay adopts many of MaxProp's optimizations in decisions about packet
delivery and peer selection, including optimizations where peers are weighted on
their temporal distance (the delta of the time between when a message was sent
and a response was received).
Stream Relay's atomic unit of data is a re-framed UDP packet. A key concept is
that packets have IDs that are a sha-256 hash of their content and potentially a
previous packet ID. Packets are encrypted and causally linked so that they can be
delivered in any order by any peer and the recipient can become eventually
consistent even under frequently changing or adversarial network conditions.
In simpler terms, this means Alice can send messages to Bob, even if Bob goes
offline. Messages can persist in the network, moving from peer to peer until they
run out of hops or they are expired and evicted from a peer's cache.
All network packets are encrypted and unless you have the key to decrypt the
packet you will never know what's in it. This is critical, because a packet may
be buffered
and relayed by a peer who is not related to your cluster.
Consider for example all the other peers in your cluster are offline, but you
want to send a packet to them, and the packet will be buffered into the network
— when the other peers come back online they can receive the packet since
it is causally linked.
In the figure above, a peer (blue solid line) from Application A wants to send
a packet but all other peers are offline, the packet will be buffered to other
peers who are members of completely unrelated clusters. This is not the exact
route that packets will take, but it roughly illustrates how some copies of the
packet will become lost or redundant. The dotted black lines represent queries
by the peers who rejoin the network and become eventually consistent.
When you publish to the network, 3 peers are selected. The peer selection
process is weighed on the temporal distance and availability of peers (the delta
of the time between when a message was sent and a response was received, as well
as the average uptime of a peer). The process of picking which messages to send
is based on what is directly requested, but also which packets have the lowest
hop count.
Each of the selected peers in turn will cache the packet for a 6-hour TTL and
replicate the packet increasing the packet's hop count until it reaches 16 at
which point it is dropped. When the packet expires, it is rebroadcast one last
time to 3 random peers in the network. This approach is effective for reaching
the majority of intended peers, and in the case a packet isn't delivered, the
recipient only needs 1 of N packets to query the network for a missing packet.
Both P2P and Cloud platforms are distributed systems that rely on eventual
consistency for most of what they do. But how we measure performance in both is
very different, mostly because of their network topology.
In client-server, metrics like P99 help measure the performance of a cloud
service behind a single endpoint. Let’s say you have 100 requests; you expect
99 responses with less than (or equal to) a specified latency.
Metrics like these work in a many-to-one model (many clients to a single endpoint).
But P2P networks are a many-to-many model. Peers also have unpredictable latency,
they may be online infrequently or for unpredictable durations.
In the topology we're describing, we measure how long it takes for a cluster to
become eventually consistent. Or how long it takes for a query packet to find a
particular packet. Trace-route packets provide some insight as to how information
is flowing through the network.
Here the Y axis is network size (±150 peers), and the X axis is time (a
15-minute sample). Each peer has an average lifetime of ±24 seconds.
Peers joining the network are represented by a green line. And peers leaving
the network are represented by a red line. In this sample set we see a total
network change of ±39900.00% — 100% being the initial size of the
network).
This chart tracks a single packet that reaches ±91.84% of the subscribed
peers in less than <0.72 seconds (before any queries are needed). A solid
black line represents the peers that have received the packet, while the
dotted black line above it represents the total number of peers that want to
receive it.
Note: as the global network grows, response times improve, packets can
live in the network longer, and increased packet volume is offset by the
increased volume of peers.
Protocol Cost
The average cost distribution to each peer in the network is ±0.000205Mb, with
a message redundancy of ±0.017787%. This is a nominal cost compared to the cost
of the average Web page (results varied widely, these are averages over
±50 runs). As with the Plumtree paper, control packets are not factored into
the total network cost.
Site
Initial Pageload
1st 15s of clicks/scrolling
discord.com
± 28Mb
± 5Mb (and climbing)
twitter.com
± 9Mb
± 18.5Mb (and climbing)
google.com
± 4.5-6Mb
± 70Mb (every click reloads content)
yahoo.com
± 36Mb
± 80+Mb (and climbing)
Why UDP?
Most modern protocols, like HTTP3 are built on top of UDP.
TCP was historically considered an ideal choice for packet delivery since it's
considered "reliable". With TCP packet loss, all packets are withheld until all
packets are received, this can be a delay of up to 1s (as per RFC6298 section
2.4). If the packet can't be retransmitted, an exponential backoff could lead to
another 600ms of delay needed for retransmission.
In fact, Head-of-Line Blocking is generally a problem with any ordered stream,
TCP (or UDP with additional higher-level protocol code for solving this problem).
This is undesirably in an extremely volatile network topology where packets will
never be sent because of peers leaving the network suddenly and frequently.
UDP is only considered "unreliable" in the way that packets are not guaranteed
to be delivered. However, UDP is ideal for P2P networks because it’s message
oriented and connectionless (ideal for NAT traversal). Also because of its
message-oriented nature, it's light-weight in terms of resource allocation. It's
the responsibility of a higher-level protocol to implement a strategy for
ensuring UDP packets are delivered.
Stream Relay Protocol eliminates Head-of-Line blocking entirely by reframing
packets as content-addressable Doubly-Linked lists, allowing packets to be
delivered out of order and become eventually consistent. Causal ordering is made
possible by traversing the previous ID or next ID to determine if there were
packets that came before or after one that is known.
In the case where there is loss (or simply missing data), the receiver MAY
decide to request the packet. If the peer becomes unavailable, query the network
for the missing packet.
The trade-off is more data is required to re-frame the packet. The average
MTU for a UDP packet is ~1500 bytes. Stream Relay Protocol uses ~134 bytes
for framing, allocating 1024 bytes of application or protocol data, which is
more than enough.
Before you start, there are two types of communication to consider. Indirect,
and direct.
Streaming
When two peers are online, it's easy to connect them and stream an unlimited
amount of data between them. This mode is ideal for things like audio and video.
Not everyone is always online at the same time! In this case, your message will
be encrypted, broken up into little pieces called packets and published to random
peers in the network. There will be a selection bias for peers in your cluster.
So it's most likely that people who you know will help buffer this data. Packets
are not only encrypted but also causally linked, which means they can be received
by any peer in any order and you will become eventually consistent with your subcluster.
This section describes the intended behavior of program execution. behavior
is defined as a sequence of states. A state is the assignment of values to
variables. A program is modeled by a set of behaviors: the behaviors
representing all material executions.
┌──────┬─────────┬──────┬───────┬───────┬─────────┬──────────┬──────┬─────┐
│ TYPE │ VERSION │ HOPS │ CLOCK │ INDEX │ CLUSTER │ PREVIOUS │ NEXT │ TO │
│ 1b │ 1b │ 4b │ 4b │ 4b │ 32b │ 32b │ 32b │ 32b │
├──────┴─────────┴──────┴───────┴───────┴─────────┴──────────┴──────┴─────┤
│ MESSAGE BODY │
│ 1024b │
└─────────────────────────────────────────────────────────────────────────┘
The previousId is used for causal ordering and MAY be the packetId of a
previous packet. Causality is NOT history (happened before). The clock
property is a logical clock that indicates historical ordering. The nextId
will only exist in cases where the packet is fragmented so that it can meet
the requirements of the MTU.
┌──────────────>─────┐ ┌┈ ┈
┌─────┼──<────┐ │ │
┌──────┬─────┬──┴─┬───┴──┐ ┌──┴───┬─────┬──┴─┬───┴──┐
│ PREV │ ... │ ID │ NEXT │ │ PREV │ ... │ ID │ NEXT │
├──────┴─────┴────┴──────┤ ├──────┴─────┴────┴──────┤ ...
│ MESSAGE │ │ MESSAGE │
└────────────────────────┘ └────────────────────────┘
Peer
structPeer {char[32] address; // the ip address of this peerchar[32] port; // the numeric port of this peer
string peerId; // the unique id of the peer, 32 bytes
NAT natType; // the type of the nat in front of this peer
string clusterId; // the cluster id of this peer
string pingId; // a string (the last pingId received from this peer)time_t lastUpdate; // unix timestamp when this peer was updatedtime_t lastRequest; // unix timestamp when a request was made to this peertime_t distance; // the delta between .lastUpdate and .lastRequest
uint64 geospacial; // the 64-bit unsigned int that represents this peer geolocation
};
Constants
Name
Description
KEEP_ALIVE
the average time that a NAT retains a port mapping, initially 30_000
PEERS
a list of Peer to connect to (read from disk or hard-coded)
CLUSTERS
a list of cluster ids for a peer to subscribe to (read from disk or hard-coded)
States
All states apply to all peers, a peer MUST not have unique properties
or states in order to maintain network symmetry.
STATE_0 (Initial)
0. Description
Initially, Peer A may not be addressable directly (because of its NAT).
However, the details needed to address it can be discovered by coordinating with
other peers located outside its NAT.
Coordination starts when peer A sends a packet to peer B and peer C.
B responds to A with A's public-facing IP_ADDRESS and
PORT. If C also responds with the same address, and port, A's
NAT is Easy. If the port number is different, A's NAT is
Hard. If C can send a packet directly to A on a well-known port,
A's NAT is Static.
Here's an analogy. You don't know what you look like, but a mirror can tell you.
If you look in a second mirror and see the same thing, you know the first mirror
is correct.
0. Topology
0. Procedure
Start an interval-function repeating at KEEP_ALIVE
Request this peer's NAT, external IP_ADDRESS and PORT
Select 2 random peers from PEERS with a NAT that is Easy or Static
Send each peer Packet<Ping>
Each peer that receives the packet will enter STATE_1
STATE_2 must be completed before the peer can enter a higher state
AFTER STATE_2 has been completed
For each known Peer
IF now - peer.lastUpdate > KEEP_ALIVE, delete the peer
ELSE GOTO STATE_1
For each cached Packet
IF the packet has expired (packet.timestamp > now - packet.ttl)
Decrement packet.postage (which starts at 8) by one
IF packet.postage > 0
multicast to at least 3 peers
ELSE delete the packet from the cache
STATE_1 (Ping)
1. Description
When a peer sends a Packet<Ping> and it is received, the Ping sequence
is started. This data structure extends the Packet struct.
IF p.message.isConnection is true, the packet is a response to an attempt to initialize a connection.
SET this peer's .lastUpdate property to the current unix timestamp
find the peer in this peer's list of peers and SET its .pingId to p.message.pingId, this will be observed by any interval-functions that have been started in STATE_3.
IF p.message.testPort was provided
SET this peer's NAT type to Static
ELSE IF p.message.pingId was provided AND this peer's .reflectionId property is null
SET this peer's .reflectionId to p.message.pingId so that it can be checked the next time this state is entered.
SET this peer's NAT type to Easy
ELSE IF p.message.pingId was provided and it is equal to this peer's .reflectionId
IF p.message.port is equal to this peer's port
SET this peer's NAT type to Easy
ELSE SET this peer's NAT type to Hard
send a Packets<Ping> with .heartbeat = true to the peer that sent p.
STATE_3 (Intro)
3. Description
In STATE_5 the two peers are "introduced", meaning they now both know each
other's external IP address and port. The next part of the process is known as
hole punching. The peer doing the introduction will send a Packet<Intro>
to A with the public IP_ADDRESS and PORT of B, and at the same time send
B the public IP_ADDRESS and PORT of A.
The first ping does not expect a response. It is only sent to open a port.
NOTE Support for port mapping protocols is scheduled for version 2 of this protocol.
3. Topology
3. Procedure
LET p be the received Packet<Intro>
IF this NAT is Easy AND p.message.natType is Easy OR Static
send Packet<Ping> to the peer at p.message.address on p.message.port
ELSE IF this NAT is Easy AND p.message.natType is Hard, apply BDP strategy ("Easy" side)
Send nPacket<Ping> messages from our main port to unique random ports at p.message.address. On average it will take about +/- 250 packets. Sending only 250 packets would mean that the connection succeeds 50% of the time, so try at least 1000 packets, which will have a 97% success rate. Give up after that in case the other peer was actually down or didn't try to connect. These packets should be sent at a short interval (ie, 10ms). This gives time for response messages. If a response is received then stop.
ELSE IF this NAT is Hard AND p.message.natType is Easy, apply BDP strategy ("Hard" side)
Send 256Packet<Ping> from unique random ports to p.message.port. This means binding 256 ports. The peer may reuse the same ports for subsequent requests. These packets are necessary to open the firewall for the Easy side, and should be sent immediately.
.peerId MUST be set to this .id
.natType MUST be set to this .nat
ELSE IF this NAT is Hard AND p.message.natType is Hard
Send Packet<Intro> to other peers who have a NAT that is NOT Hard
STATE_4 (Publish)
4. Description
Peers may communicate directly or indirectly. This is a VERY important distinction
in this protocol.
When a peer has established communication with another peer, it can stream bytes
directly — this is most useful for applications like video or audio, or
real-time "multiplayer" communication.
The published state, and the method that should publish a packet, are for indirect
communication — it may be used to get set up for direct communication, or
for a chat or social app for example. An application should publish
Packet<Publish> when the intended recipient is known to be offline or does not
respond to a ping. The packet will be encrypted and eventually, it will be
received by the intended recipient who also subscribes to the clusterId.
4. Topology
4. Procedure
LET p be an instance of Packet<Publish>
IF Peer A is publishing a packet
Peer A will construct a Packet<Publish>
SET p.clusterId to its own cluster id
IF a packet's message is larger than 1024 bytes (In consideration of UDP's MTU)
The packet must be split into smaller packets and each packet must be assigned p.index
SET p.packetId to sha256(p.previousId + p.message + p.nextId) (p.nextId may be empty)
SET p.hops to 0
Peer A must increment its own .clock property by one
Peer A must select 3 peers to send the packet to
IF Peer A's NAT type is Hard`
exclude peers with NAT types that are Hard
Sort peers by .distance (the last delta of time between a ping and pong)
ELSE IF Peer A is receiving a published packet
IF Peer A has already seen the packet with p.packetId, it should discard the packet
this state ends here
ELSE Peer A has never seen the packet it should add it to its cache
Peer A should select 3 random peers to replicate the packet to
Peer A must choose the larger .clock value (its own, or the value in the message)
Peer A must increment its own .clock property by one
IF p.hops > 16 the state should end here
IF Peer A's .clusterId is equal to p.clusterId decrement p.hops by 2
ELSE decrement p.hops by 1
Peer A must select 3 peers to send the packet to
IF Peer A's NAT type is Hard`
exclude peers with NAT types that are Hard
exclude the peer that sent p
STATE_5 (Join)
5. Description
A peer sends the Packet<Join> packet when it comes online. This procedure
will introduce peers and prompt them to go to STATE_3 (Intro).
5. Topology
5. Procedure
LET Peer A be the peer that wants to join the network
LET Peer B be a peer that is outside Peer As NAT
LET Peer C be a peer that is known to Peer B
LET p be the Packet<Join> sent by the remote peer
LET p.message.clusterId be the cluster that the peer wants to join
Peer A sends p to Peer B
Peer B MAY concurrently enter into STATE_6 if it has a NAT type of Easy or Static
Peer B prepares Packet<Intro> to introduce the peer sending p and a selection of known peers
IF a peer has a NAT type of Hard and p.message.natType is Hard, an introduction will not be made
Peer B MAY concurrently send
Packet<Intro> to Peer A that contains the info about Peer C
Packet<Intro> to Peer C that contains the info about Peer A
IF Peer C receives Packet<Intro> from Peer B it will enter into STATE_3
IF Peer A receives Packet<Intro> from Peer B it will enter into STATE_3
STATE_6 (Exchange)
6. Description
After two peers have established the ability to exchange packets. They may enter
into an exchange state. This state is started when a peer sends a Packet<Query>
and it is received by another peer.
6. Topology
6. Procedure
LET Peer A be the peer sending the query
LET Peer B be the peer receiving the query
LET p by the Packet<Query> packet sent by the remote peer.
IF Peer B's cache includes p.packetId
IF p.message.tail is true
IF Peer B's cache contains p.packetId and has the previous packet
send Peer A the packet as Packet<Answer>, include the prior .previoudId as a suggestion
ELSE send Peer A the next packet as Packet<Answer>, include the following .packetId as a suggestion
IF Peer A receives a suggestion, it may decide to continue as many times as it wants
Peer A MAY send 3 random packets to Peer B which has the lowest number of hops in the cache
Peer B MAY send 3 random packets to Peer A which has the lowest number of hops in the cache
Socket supports native extensions in C/C++. But you can write your program in
any language if it can be compiled to WASM.
In this guide, we will walk you though creating a native extension that can
also be compiled to a WASM extension. There is an official collection of
native extension examples here.
Native Extensions
Initialize a new project in an empty directory with ssc init.
C/C++
Create a file called ./src/extension.cc in your project.
If for example you want to create a Rust program, just point your tool-chain at the
correct files. Use the socket/extension.h C ABI and you get access to the environment
in a way you'd expect to in C/C++.
Socket can create a complete boundary between all developer code and user's
operating system.
This is in sharp contrast to Electron or Tauri, whose Node and Rust portions of
the code run unrestricted and without policy on a user's operating system.
Backend / Main Process
Socket also supports this concept, although we consider it legacy and don't
recommend starting new projects this way.
01 Problem
The typical approach for most solutions is to separate UI and "business" logic
into two sub-programs that run adjacent to each other. The one with the
"business" logic is usually called the "main" or "backend" process.
Business logic is just code that has no relation to the UI at all, it can usually
be treated like a black box, it takes input, it gives us output. An example could
be a complex financial calculation written in Python or FORTRAN. It can sometimes
be compute-intensive, so the primary purpose for this separation is to avoid
degrading the performance of the UI thread.
Historically, this separation has also been thought of as a security best practice
because traditionally the frontend may execute less trusted 3rd party code, it may
even execute entirely untrusted arbitrary remote code, and if the frontend code
can escape to the backend it can gain access to the host computer.
Also historically, the backend code is the primary code, driving the UI and
any other aspects of the software. This is where the problem begins. Modern
backend programs are composed of many layers of modular dependencies. This code
can consume data from 3rd party services, it may (directly or indirectly)
execute less trusted 3rd party code, and it may even execute entirely untrusted
arbitrary remote code. This is a problem on desktop because most Operating
Systems have little to no sandboxing faculties compared to mobile. Most desktop
apps or programs in general can read your files, use your camera, record your
screen, record your keystrokes, and even hold your computer hostage for a ransom.
A rouge backend, or a deeply buried transient dependency with malicious behavior
can be equally as effective as any other attack vector through the frontend.
02 Solution
First of all, we advise never executing arbitrary remote code, or using untrusted
3rd party code that you haven't audited, in any area of your software. Avoid
loading remote websites into Socket Runtime. We especially do not recommend
building a browser with Socket Runtime. This is a very complex problem and Socket
runtime is not an appropriate solution for this.
While Socket Runtime has the ability to create a backend process, it's completely
optional, and we don't consider it the best practice. If you are shipping highly
sensitive IP you may choose to put it here. If you have to compute intensive
code, you can also put it here. But ideally this is a use case for a worker or
for WASM.
Socket Runtime is characterized as a "runtime" because of the primary mode in
which it is intended to operate; ALL developer code is run dynamically, inside
the compiled program which sets boundaries between the code it runs the
operating system that it runs on.
Socket apps can be written entirely in JavaScript, CSS, and HTML. This way, ALL
application code can be entirely contained in the runtime. The runtime can be
signed and hashed, it should always have the same fingerprint. The contained
developer code, which may be more dynamic, is made secure by the way we uniquely
leverage the CSP (a well-established web standard), which can be inspected
prior to running the program.
Invocation of filesystem, bluetooth, network, etc. is all made over IPC calls
that use a URI scheme (ipc://...), because of this, CSP maintains control
over the decision to allow their execution. these calls never hit the network,
they are handled internally using custom schemes so they never leave memory and
do not have the same IO cost as issuing a regular network call.
Any curious user can run a command like strings foo.app | grep ipc:// on a
socket app bundle and examine the CSP of the index file.
While its true, other platforms offer different ways of working with CSPs, they
are not creating a full boundary between all developer code and the user's OS.
Networking
TODO
Reporting Security Issues
If you find a security issue, we provide a process to responsibly disclose
potential vulnerability. We will also make every effort to acknowledge your
work.
We will work with you the the entire lifecycle of the issue. From the time
you report it, to the time it has remediation, and is ready for an announcement.
Comparison Guide
These are similar enough that people ask about them frequently. However, they have somewhat different goals...
Socket runtime normalizes the differences between WebViews on different operating systems. Critical APIs we have made uniform for example are, fetch() (including Request, Response, and Headers), URL, geolocation, navigator.permissions, Notification API, File API, file system access and file pickers
Performance
Stat
Socket
Electron
Tauri
Baseline Build Size
±1MB
±220MB
±1.8MB
Build Time
±1.52s
±20s
±120s
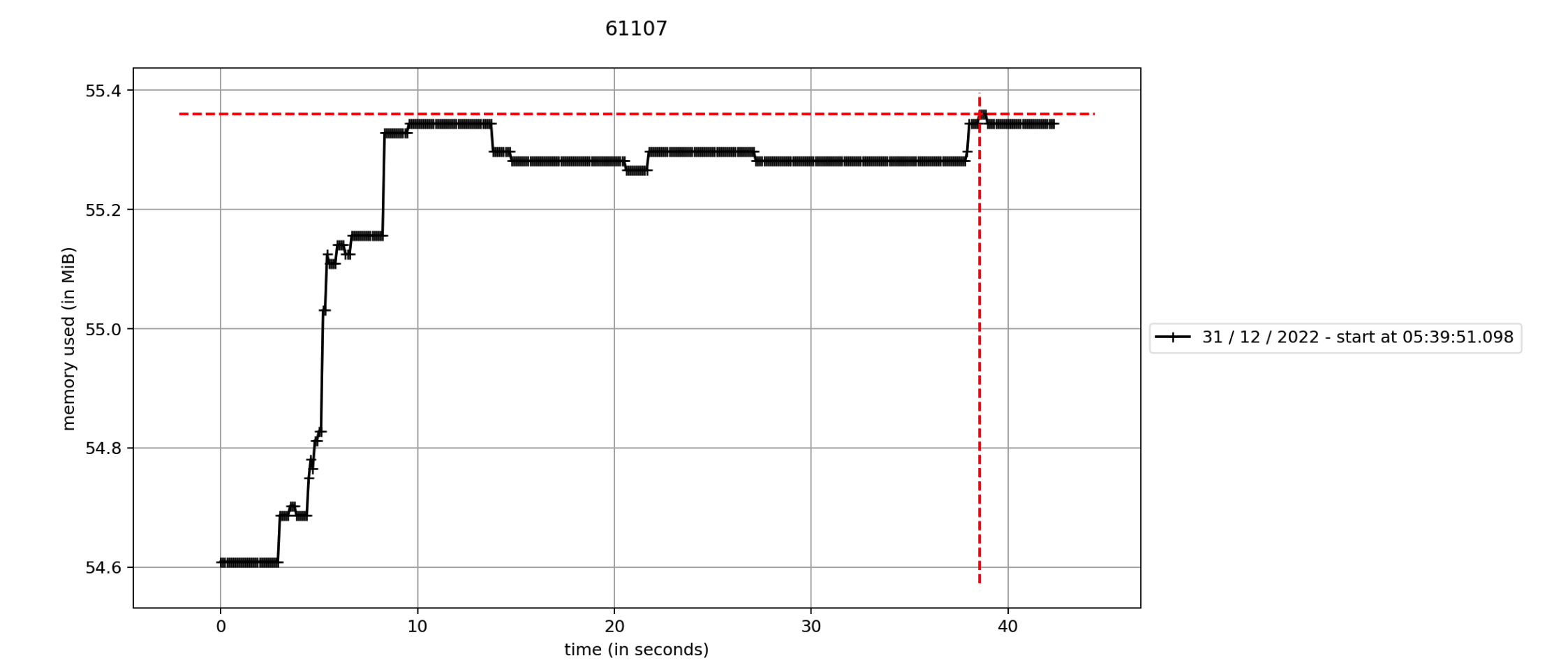
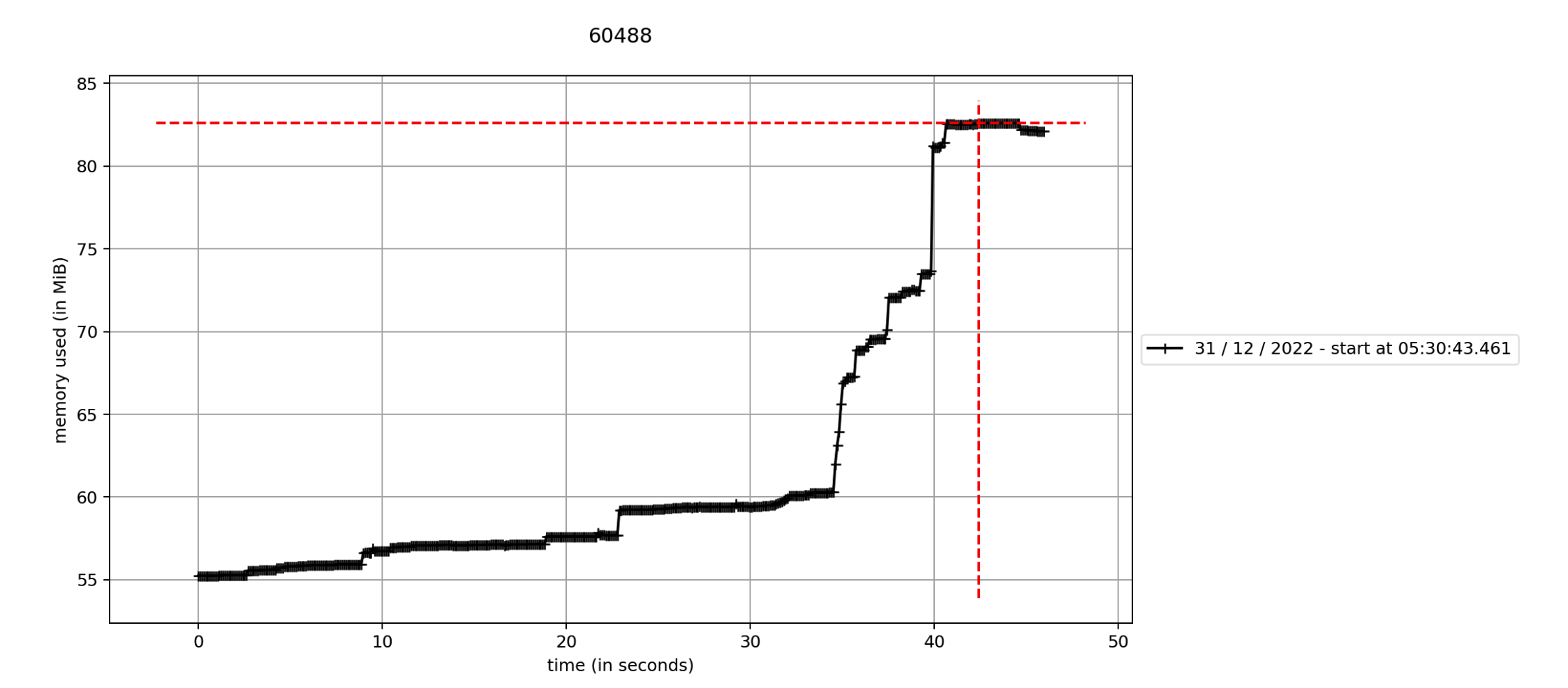
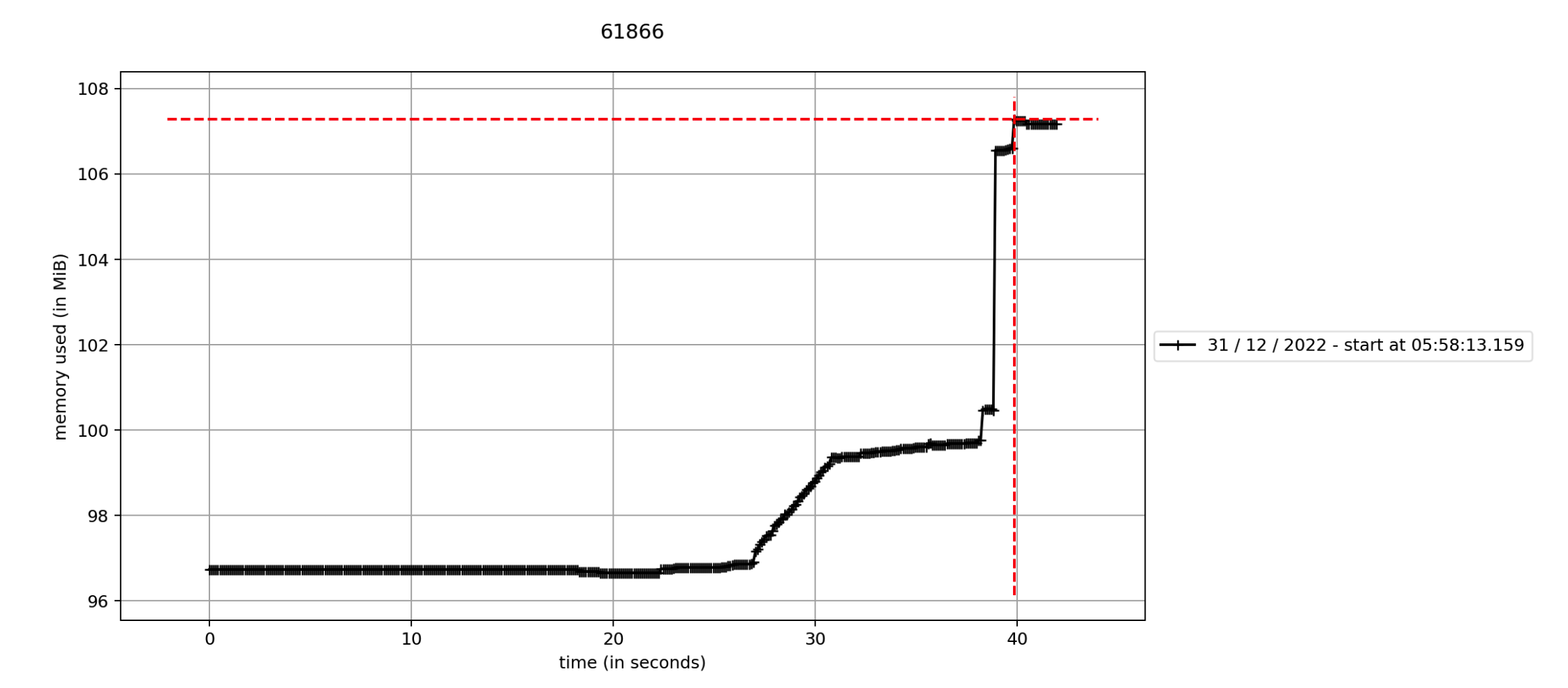
Memory Profile Summary (Desktop only, measured with `mprof`)
±55.4 Socket
±85Mb Tauri
±108Mb Electron
Backend Memory Usage was tested with a program that just listens to stdin and writes to stdout, for socket it was written in C++.
Frontend Memory Usage was tested with the default Hello world
Socket
Tauri
Electron
Troubleshooting
CLI
aclocal / automake: command not found
To build ssc from source for ios you need automake / libtool installed.
brew install automake
brew install libtool
unable to build chain to self-signed root for signer (...)
You need the intermediate certificate that matches your code signing certificate.
To find which "Worldwide Developer Relations" matches your certificate, open the
signing certificate in your keychain, open this
page, and find the certificate that matches the details in the "Issuer" section
of your certificate.
xcrun: error: SDK "iphoneos" cannot be located
You have to configure the Xcode command line tools, to do this
you can run the following command
You have not agreed to the Xcode license agreements, please run 'sudo xcodebuild -license' from within a Terminal window to review and agree to the Xcode license agreements.
You can run sudo xcodebuild -license to agree to the license.
Multiple Password Prompts
If macOS is asking you for a password every time you run the command with -c flag,
follow these instructions
Application crashes on start
If you use iTerm2 you can get your app crash with
This app has crashed because it attempted to access privacy-sensitive data without a usage description. The app's Info.plist must contain an NSBluetoothAlwaysUsageDescription key with a string value explaining to the user how the app uses this data.
Command line apps inherit their permissions from iTerm, so you need to grant Bluetooth permission to iTerm in macOS system preferences. Go to Security & Privacy, open the Privacy tab, and select Bluetooth. Press the "+" button and add iTerm to the apps list.
MacOS
Crashes
To produce a meaningful backtrace that can help debug the crash, you'll need to
resign the binary with the ability to attach the lldb debugger tool. You'll
also want to enable core dumps in case the analysis isn't exhaustive enough.
sudo ulimit -c unlimited # enable core dumps (`ls -la /cores`)
/usr/libexec/PlistBuddy -c "Add :com.apple.security.get-task-allow bool true" tmp.entitlements
codesign -s - -f --entitlements tmp.entitlements ./path/to/your/binary
lldb ./path/to/your/binary # type `r`, then after the crash type `bt`
Clock Drift
If you're running from a VM inside MacOS you may experience clock drift and the signing
tool will refuse to sign. You can set sntp to refresh more frequently with the following
command...
sudo sntp -sS time.apple.com
macOS asks for a password multiple times on code signing
Open Keychain Access and find your developer certificate under the My Certificates section.
Expand your certificate and double-click on a private key. In the dialog click the Access Control tab.
codesign utility is located in the /usr/bin/codesign. To add it to the allowed applications
list click the "+" button to open File Dialog, then press ⌘ + Shift + G and enter /usr/bin.
Select codesign utility fom Finder.
Windows
Development Environment
The quickest way to get started on Windows is to use .\bin\install.ps1 from within the cloned source socket repo:
.\bin\install.ps1
This will install vc_redist.x64.exe, git, cmake and Visual Studio Build Tools including clang++ version 15, nmake and the Windows 10 SDK using vs_buildtools.
If you would like to verify your installation, you can run vsbuild manually using our .vsconfig:
vsbuild.exe bin\.vsconfig
Powershell Scripts
By default Powershell is locked down to prevent user script execution.
You may see this error:
./bin/install.ps1 : File C:\Users\user\sources\socket\bin\intall.ps1 cannot be loaded because running scripts is
disabled on this system. For more information, see about_Execution_Policies at
https://go.microsoft.com/fwlink/?LinkID=135170.
The full set of tools and assets required for building Windows apps and ssc from source entails about 4.6GB of download data from Microsoft's servers.
The total extracted size of the Windows build tools is 11.7GB.
Download time estimates:
Connection Speed*
Estimated Time
1Mbps
~11 hours
25Mbps
~26 minutes
100Mbps
~6 minutes
Note that these estimates don't include your development environment hardware, times will vary.
Connection speed refers to your actual data throughput to the relevant servers, which could be slower than your advertised connection speed.
Git Bash
If you find Git Bash to be more convenient, you can use it after running bin\install.ps1.
If bin\install.ps1 is allowed to install everything correctly it creates a .ssc.env file which contains the path to MSVC build tools' clang++ (The variable is called CXX in .ssc.env).
Once .ssc.env is set up, you can run ./bin/install.sh to build ssc.exe and the static runtime libraries that are used to build Socket apps.
Linux
Build failures
If you are getting a failure that the build tool can't locate your
compiler, try making sure that the CXX environment variable is
set to the location of your C++ compiler (which clang++).
For debian/ubuntu, before you install the packages, you may want
to add these software update repos here to the software
updater.
Note that clang version 14 is only available on Ubuntu 22.04. Use clang 13
for prior versions of Ubuntu.
arch uses the latest versions, so just install base-devel
sudo pacman -S base-devel
Can't find Webkit
If you run into an error about not finding webkit & gtk like this:
Package webkit2gtk-4.1 was not found in the pkg-config search path.
Perhaps you should add the directory containing `webkit2gtk-4.1.pc'
to the PKG_CONFIG_PATH environment variable
No package 'webkit2gtk-4.1' found
In the file included from /home/runner/.config/socket/src/main.cc:9:
/home/runner/.config/socket/src/linux.hh:4:10: fatal error: JavaScriptCore/JavaScript.h: No such file or directory
4 | #include <JavaScriptCore/JavaScript.h>
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Then you will want to install those dependencies
sudo apt-get install libwebkit2gtk-4.1-dev
libwebkit2gtk-4.0-dev on Ubuntu 20
To date, most of our efforts have focused on working with libwebkit2gtk-4.1-dev.
While we did spend some time testing libwebkit2gtk-4.0-dev, we came to the conclusion that it may be unstable.
For the near term, libwebkit2gtk-4.0-dev is out of scope for Socket Runtime.
Android on Linux arch64 / arm64 build host support
Currently static libraries and apps can't be built on Linux aarch64 due to ndk incompatibility:
/home/user/Android/Sdk/ndk/25.0.8775105/toolchains/llvm/prebuilt/linux-x86_64/bin/clang --target=aarch64-linux-android -v
/home/user/src/socket/bin/functions.sh: line 26: \
/home/user/Android/Sdk/ndk/25.0.8775105/toolchains/llvm/prebuilt/linux-x86_64/bin/clang: \
cannot execute binary file: Exec format error
NDK does not ship with Linux/aarch64 compatible binaries:
Note: MacOS aarch64 is supported by NDK 25.0.8775105
FAQ
How is Socket different from other cross-platform solutions such as Electron, Fultter, Tauri, NativeScript, React Native, Ionic, etc?
Socket is for Web developers, there is no new language to learn (such as Dart or Rust).
Socket is the first and cross-platform runtime built from the ground up
for desktop and mobile, others may retrofit but it will be hard to maintain.
Socket embraces web standards instead of inventing new paradigms.
Socket is actually a runtime in that it can create a full boundary between all developer
code and the user's operating system. This is far more secure than any other approach.
P2P and local-first are first-class considerations. We provide
JavaScript APIs for Bluetooth, UDP, and robust file system IO. These make it
possible to create an entirely new class of apps that are autonomous from the
cloud and allow users to communicate directly without any infrastructure
requirements.
Why should I care about P2P?
P2P features allow a developer to create apps where users can communicate
directly, without the Cloud. It does not require any servers at all, and even
works when users are offline. These features are optional, they are NOT turned
on by default and won't interrupt or conflict with your existing architecture
or services.
Can I revoke access to data with P2P like I can with a web service?
Yes! Obviously with something like Google Drive people can copy files out, or
with applications like Notion people can just copy the content to somewhere else.
In terms of an equivalent P2P behavior, application data can be expired by encoding
a time-to-live into the data, and rotating keys in the network cluster. When a peer
is unable to retrieve the next key in time, the data becomes unreadable.
Can Socket Apps run and be compiled headlessly?
Yes. This makes it great for creating Web developer tooling since it has a
native DOM and all the browser APIs built in.
How can I trust what Socket is doing on my computer?
Socket is open-source. We would love for you to read all our code and see how
we're doing things! Feel free to contact us as well and we can walk you through
it.
But you're also a business, so you have to have some private technologies that you charge for, to make money?
As stated above, Socket Supply Co. builds and maintains a free and open source
Runtime that helps web developers build apps for any OS, desktop, and mobile, as
well as a p2p library, that enables developers to create apps where users can
communicate directly, without the Cloud.
These will always be open-source and free to use by any developer, no matter
what they use them for (commercial or personal). That will always be true.
Our Operator App has different tools which help in the entire lifecycle of
building, deploying, and monitoring the Socket apps you build. Operator App has
various pricing tiers which hackers, startups, and enterprises can benefit from.
We already have teams of engineers that build our web and other native-platform app experiences. Why would we benefit from Socket?
App builders can prioritize what they want to solve when working with Socket.
There are many benefits to choose from for a wide variety of reasons.
Cost reduction — For smaller teams who don’t have native teams in place,
they can get to their customers quicker by writing once, and running anywhere.
Cloud bills are the #1 cost for many organizations, building on Socket reduces
that to $0, or as much as you want to migrate off the cloud. We say crawl, walk,
run.
Autonomy — Right now you’re entirely codependent on a 3rd party to run a
mission-critical part of your business. The Cloud is a landlord-tenant
relationship with costs that can prevent your business from becoming profitable.
Socket helps you connect your users directly to each other, allowing you to rely
less on the Cloud, and reclaim your sovereignty, and your profit margins.
Complexity — Companies whose applications are built across desktop and
mobile would be moving from working and maintaining >= 3 code bases in their
current state to 1 code base with Socket. This drastically reduces complexity
within the organization and speeds up feature releases.
Builders of network-enabled Productivity and Collaboration tools will realize
major benefits by building on Socket. Evan Wallace, Co-founder of Figma said
it best "these days it’s obvious that multiplayer is the way all productivity
tools on the web should work, not just design."
Is this somehow related to Web3?
If we define "web 3" to mean a decentralized web, then yes. We don’t really take
a position on anything else. We provide a technical foundation that makes it
possible for many Web3 ideals to come to fruition.
In its current state, Web3 is not decentralized. The ecosystem relies heavily on
centralized cloud providers like AWS for infrastructure. This is an economic
disadvantage and in most cases a barrier to entry. However, apps built with
Socket’s P2P capabilities can be 100% decentralized, and absolutely no servers are
required. They can be fully autonomous, aligning directly with the mission of
the web3 community.
Does P2P (without servers) mean that it only works if peers are online?
No! Socket's P2P protocol is designed for building disruption tolerant networks.
It achieves long-lived partition tolerance through bounded replication of
packets (limiting the number of hops and TTL of each packet that is relayed
between peers in the network). Socket's P2P protocol builds on a corpus of
existing academia. Please see the docs for more in-depth details.
If I send information to my friend or coworker, any other connected peer devices will see this message as they relay it on?
Peers do all relay packets for each other, to ensure that any peer can
communicate with any other peer, even if they aren't directly connected or ever
online with each other at the same time.
However, all data packets (those used for user data, not network coordination)
are encrypted, such that only the intended recipient of the packets can decrypt
and access the information therein.
So your message will reside in parts (packet by packet) on many other users'
devices, at various times, but only in parts and only encrypted, meaning those
other devices cannot make any sense of that data.
This encryption/decryption security uses industry-standard -- and is audited! --
public key cryptography, similar to -- and at least as safe as! -- the
HTTPS/TLS encryption that users across the web trust for communication with very
sensitive sources, including banks, doctors, etc.
I am nervous about other people transmitting arbitrary information that may be on my device, because this information could open me up to liability (legal, etc). How am I protected if I allow my device to relay information for others I don't know or trust?
Your device never holds plain-text (or plainly accessible) data on behalf of any
other user. The packets your device relays on behalf of others were encrypted for
those intended recipients, and your device could never possibly decrypt or make
sense of any of that data.
You thus have perfect deniability as your protection from those potential
risks and liabilities.
This is analogous to internet infrastructure like switches/routers, which are
peppered by the billions around the web. None of these devices can decrypt the
HTTPS traffic transiting through them, and thus none of those devices ever have
any liability for the kinds of information buried inside the encrypted data as
it flows through.
Socket isn't introducing anything more dangerous here than has already existed
for the last 25+ years of the internet.
More importantly, the relay of packets through your device only happens
in memory (never on disk), and only while you have a Socket powered app open
for use. If you close the app, or power-off / restart your device, that cache is
wiped completely; the in-memory cache only gets filled back up with more packets
when you open a Socket powered app while online.
As the device user, it's always your choice and in your control.
Does this mean that other people can use my device for performing heavy computations (bitcoin mining, etc) without my consent?
No!
The P2P relaying of packets is merely a pass-thru of (encrypted) data. Your
device performs almost no computation on these packets, other than to check the
plaintext headers to figure out whether and how to relay it along.
Aside from this very simple and fast processing of these packets, your device
will never perform any computation on behalf of any other person.
The only exception would be computation you had directly and expressly
consented to via an app that you chose to install and open/use, if that app
was designed in such a way to share computation work with others.
For example, "SETI@home" type apps intentionally distribute computation (image
processing, etc) among a vast array of devices that have idle/unused computing
power being donated to a good cause. Another plausible example: some apps are
currently exploring distributing machine-learning (ML/AI) computations among an
array of peers.
If you installed such an app, and opened it, your device would subject itself to
app-level computation on behalf of others. But you remain in control of all
those decisions, including closing such apps, uninstalling them, etc. And if you
didn't install and open such an app, none of that distributed computation would
ever happen on your device, regardless of how others use the P2P network.
No unintended/background/abusive computation on your device is ever be possible
by virtue of the Socket P2P protocol itself. Only apps themselves can coordinate
such distributed computation activities, and only with expressed installation
consent from users.
Aside from CPU computation, doesn't allow my device to participate in packet relay for many other peers subject my device to extra resource utilization (using up my memory, draining my battery more quickly, etc)?
The only resource utilization that occurs is that which you consent to by
opening and using Socket apps.
Socket limits the memory used for the packet relay cache, currently to 16MB
(not GB!). This is an extremely small slice of typical device memory, even
budget-level smartphones (which typically have at least 1-2 GB of memory).
As for the battery, Socket does not perform unnecessary background work, so any
battery usage you experience should be directly proportional to the active use
of a Socket powered app.
Relaying packets is a very simple and resource-light type of task. In our
testing, we haven't seen any noticeable increase in resource load on devices as
a result of running a Socket powered app, compared to any other consumer apps
users typically use.
As a matter of fact, Socket powered apps tend to use and transmit way less data
than other commercial/consumer apps, so users can expect in general to see no
worse -- and often much improved! -- resource utilization than for non-Socket
apps.
Does P2P packet relay mean that data transmission, such as me sending a text message or picture to a friend, will go much slower?
P2P packet relay, even across a broad network of many millions of devices, is
surprisingly fast and efficient, compared to typical presumptions.
If the sender and receiver of a message are both online at the time of a message
being sent and are at most a few hops away in terms of the packet relay protocol
of Socket, this transmission should take no more than a few hundred milliseconds
at most.
In fact, since this communication is much more direct than in typical
infrastructure, where messages have to go all the way out to a cloud server, and
then on to the recipient, it's quite likely that communications will be at least
as fast, if not much faster, via P2P communications techniques (relay, etc) as
described.
What happens if all the other peers go offline?
Most P2P solutions build silos of networks. And it's a problem if all the peers
you know are offline because there is no one to accept your messages and in the
majority of cases it's hard to be online at the same time as all the other peers.
Socket creates a single global network where all peers share in the responsibility
of relaying and connecting each other. At this point in time, there will never be
a case where there isn't another peer online.
If the recipient of my message is not online when I send it, how long will the packets stay alive in the network before being dropped?
There's a lot of it depends on this answer (including the size of the message,
how many packets, and network activity/congestion). But in general, messages may
be able to survive for as long as a couple of weeks and almost never less than
several days.
Apps are expected to design with the nature of the lack of delivery guarantees
in P2P networks in focus. To help users compensate and adapt, these apps should
provide appropriate user experience affordances, including "resend",
"read receipt", and other such capabilities.
How do I know that a message I receive (and decrypt) was not tampered with?
Data is encrypted at the packet level, packets are encrypted using the public
key of the intended recipient. Only the recipient (holding the paired private
key) could possibly decrypt the packet, which would be necessary for tampering.
Any man-in-the-middle tampering with an encrypted packet would render the final
decrypted value as garbage. The app would be able to immediately tell that the
expected data was garbled and thus discard it.
Corrupted (or manipulated) packets, or even dropped/missing packets, can be
automatically re-queried across the peer network, to reacquire the necessary
packets. As such, the encryption used guarantees that information received is
either complete and intact, before decryption, or entirely dropped.
As for determining the identity authenticity of the sender, the network protocol
does not employ overhead of digital signatures or verification, nor digital
certificates.
Socket apps are allowed, and expected, to employ their own security layered on
top of (tunneled through) the network encryption provided automatically. This
may include additional encryption, digital signatures, digital certificates
(identity verification), and more, according to the needs and capabilities of
the app.
All of those app-specific techniques are still leveraged and negotiated across
the Socket's peer network.
Bad actors are certainly going to try to flood the network with junk, to deny/degrade service (DoS attacks), attack peers (DDoS attacks), etc. How can this P2P network possibly survive such abuse?
Stream relay protocol includes a sophisticated set of balancing techniques,
which acts to ensure that no peer on the network places an outsized burden on
other peers in the network.
The main technique here is rate limiting. Peers set rate limits on replicated
and streamed packet types. So if you talk too much peers stop listening to you.
Is this like BitTorrent, Tor, Napster, Gnutella, etc?
These solutions are focused on file sharing. We see a broader opportunity
with P2P which is focused on connectivity, reduced infrastructure, and reduced
complexity in general.
Is Socket a Service?
Socket is NOT a cloud service. We do not have a SaaS offering. And there is no
part of this that is hosted in the cloud.
There is a complementary application performance management product (APM),
Socket Operator, that can diagnose and remediate issues within the production
apps you build. This is also not a service, it's software.